Edition Data
VEdition Architecture
Data for the VE edition is very peculiar, and represents an extreme case in authorial philology. Nonetheless, the solution adopted here may have a more general impact on editing such texts, right because its purpose is to provide models and tooling for one of the most complex scenarios, strong enough to cope with VE, yet easy to scale down.
In a more traditional approach, one of the most popular models is based on a systematic comparison of different stages of what is regarded as the same text. Each stage is a text document on its own, and gets marked to explicitly define its differences with what is usually taken as a comparison.
So, here markup becomes the link between these stages: in each document, tags mark portions which have been deleted or added with reference to another one. This is similar to a diffing operation between two documents: we compare them, and whenever they diverge, we annotate the deviation type.
A big advantage of this approach is that it allows scholars to reuse models and tools created for traditional philological scenarios, where we compare text witnesses to reconstruct a hypothetical text. In fact, here we mostly use markup from the critical edition TEI module, adapting models designed for a single text with multiple witnesses to represent multiple stages of a text.
While this is a perfectly fine approach, the VEdition scenario poses serious issues for its practical application. Here we are dealing with a work which has never got an authoritative publication, and is rather a “constellation” of texts. Our material evidence is represented by notebooks or single sheets (sometimes also letters) with multiple compositions, plus a set of printed editions with a subset of them. Many of these compositions can be easily recognized as different versions of what we can consider the “same” epigram.
In turn, manuscript texts are often a complex document, where annotations from author, revisors or editors accumulate on a “base” text to represent its alterations of any sort. Such alterations usually culminate into an alteration stage representing the final state after all changes belonging to the same hand have been accumulated. For instance, there can be a set of annotations in pencil, another one in brown ink, and another one in red ink.
So, these manuscripts literally capture in a sort of photographic snapshot a specific moment in the creative process of their text, freezing in it all the changes accumulated on the original text, from the first to the last one for that specific carrier. This rich material evidence often points to even dozens of different alterations for each snapshot.
In a sense, “snapshots” roughly correspond to “versions”. Versions are the text (or texts) present on a specific carrier for a specific epigram; while “snapshot” is a more technical term referred to the IT model used to represent all these texts (alterations) stemming from annotations combined with the base text.
So in the end, the “epigram” here is a pure abstraction: the set of all the texts with its variants, where none can be assumed as the final one. This is an unordered set of variants all related to what we recognize as a single epigram. The material support of these variants (here generically named text carrier, whether it’s a notebook, a sheet, a letter, or a printed page) is either a manuscript or a printed edition, assembled in a less or more arbitrary way in different times and with different purposes.
Finally, the versions collected in a specific sequence, whether it is materially attested (e.g. a printed edition) or it’s just suggested by annotations on snapshots (e.g. numbers on the margin of each version) represent collections.
Figure 1 summarizes the data architecture designed to represent our data:
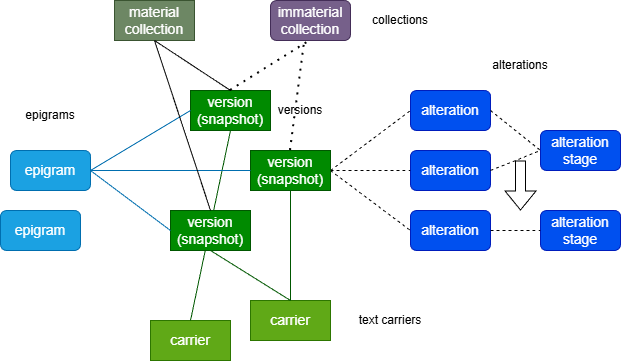
- Figure 1: main entities in VEdition architecture
In the diagram, green rectangles represent material entities, while rounded rectangles represent immaterial entities.
Note that the relationship between a material entity and a text can be complex: a version, which is a concrete entity, and as such has a facsimile image, often represents multiple alterations of a base text, rather than just a single text (like in a printed page).
It is up to scholarly interpretation to reconstruct the various alteration stages of a version according to the annotations read on it. So versions have a 1:N relationship with text, and when this relationship is not 1:1, text always derives from a reconstruction, whatever its complexity level.
So, in this architecture the notion of “text” is rather sparse:
- an epigram contains many versions. These are material entities (a text with annotations), but the texts they represent are immaterial whenever alterations are implied by annotations.
- a version contains many alteration stages. These are reconstructions, based on diplomatic and philological evidence.
- an alteration stage contains many alterations. These are the set of all changes which taken together define a single alteration stage. Each alteration derives from the interpretation of annotations.
- a collection contains selected alteration stages, usually in a specific order.
For consistency and generalization, this model applies to all texts, even in the case of printed editions or simple manuscripts with no annotations, where a version is just a single text, and thus there is no true alteration. The alteration stage is just the representation of a text derived from the version, whether it is just a reading of it, or it’s a complex reconstruction based on the analysis of hands and annotations on a manuscript.
Embracing Change
Thus, VEdition data are highly peculiar because here we cannot define a linear evolution of a work, not even with branching. This is rather a constellation of texts, grouped into variations on a same epigram, scattered across multiple text carriers and variously assembled in different collections. Rather than a genetic tree, here we deal with a graph of interconnected texts.
Also, many of these texts are reconstructions, alteration stages based on annotations found in snapshots, which witness the creative process behind each composition at a given (often undetermined) time. The best we can do to provide a faithful representation of this complex constellation is to map it with the maximum level of granularity, fully describing each version, both on the textual and visual side, with focus on the process which generates it.
In this context, an approach based on a systematic comparison of statically defined texts would be very difficult to afford in practice. Texts here are the products of dozens of alterations for each version, which in turn belong to each epigram. The Cartesian product of all the comparisons resulting from these entities would be enough to discourage such an attempt, at least if conducted manually.
Additionally, this approach would not be ideal with relation to the highly dynamic nature of this “work”. This is not a unitary literary work progressing over time, but rather a set of variations of a set of related texts; and manuscripts do witness an extensive alteration process in the creation of most of them. These alterations can be reconstructed from annotations, which hint at the genetic process behind each text version, rather than on its “final” stage, which in most cases is not even defined.
In such an elusive scenario, where everything dynamically changes like within a living organism, we need a dramatic focus shift to embrace this dynamism, rather than fighting it. Instead of trying to systematically align all these slippery “ghost” texts and leave to readers to task to mentally figure out the creative process behind their network of differences, we switch focus from the effect to the cause. All our alterations are the effect of a creative process which transforms a text: and that’s exactly what we’re going to target.
Our carriers with all their chaotic annotations are the witness of a creative process, and all the variations we collect and align are just its effects. In this digital edition, time can no longer be our enemy, but our ally. The same time which accumulated all those changes on a text, making it a puzzle for scholarly interpretation, can be the key to a more effective model of the creative process behind all this complexity.
Of course, this approach primarily stems from the nature of the core VEdition material, which is represented by often deeply annotated manuscripts. Printed texts here, which are relatively marginal, are just subsumed into this more expressive model for the sake of consistency.
Modeling Strategy
So, in our model we are going to represent all the entities described above (Figure 1), with a special focus to snapshots, which are the most complex one, composed of a lot of moving parts.
This is why modeling in this project has been developed bottom-up, starting with snapshots and their alterations, and then integrating them within the larger network of entities which orbit around them, like versions, epigrams, carriers and collections.
The core here are texts, which in the end are modeled as alteration stages (in turn grouping alterations). The version is just a set of alteration stages; the carrier is what materially contains it; the epigram is an abstraction grouping multiple versions; and the collection is a material or immaterial group of version’s alteration stages.